| 擬答 類別對類別的資料型態可以列聯表的方式呈現結果,表格中可呈現設經地位與糖尿病有無的交叉個數,例如:
|
||||||||||||||||||||||||||
擬答
|
擬答
|
| 擬答
一.
|
|||||||||
| 二.𝚀D=(𝚀₃- 𝚀 ₁)/2=(5.6-5) /2=0.3 | |||||||||
三. 設糖尿病患三酸甘油脂為Xi,高血壓病患三酸甘油脂為Yi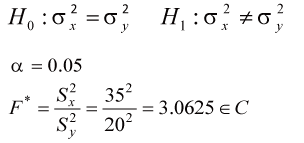
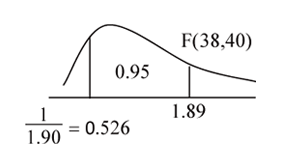 拒絕H0,所以有顯著證據說變異數不相同 |
|||||||||
四.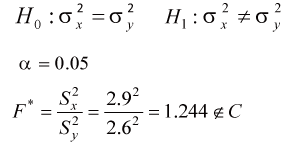
不拒絕H0,所以沒有顯著證據說變異數不相同 因為要採用變異數同質性的前提作兩組的平均數檢定,所以採用指數化後的數據作合併變異數之T檢定 |
|||||||||
五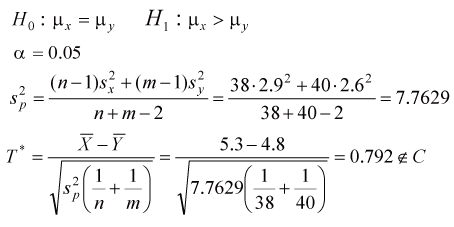
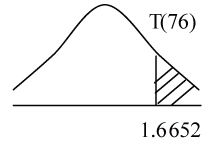 拒絕H0,沒有顯著的證據說 糖尿病病患的三酸甘油脂是高於高血壓病患的三酸甘油脂 |
|||||||||
| 六. 方法一: 若要估計原始兩組三酸甘油脂的差異,應該採用變異數不相等T分配之信賴區間 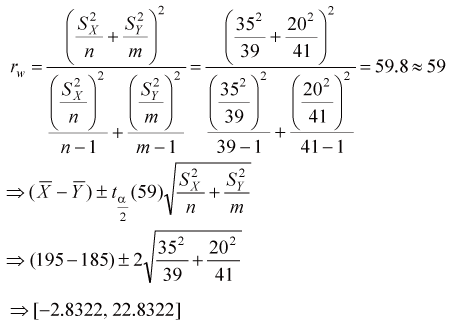
方法二: 估計指數化兩組三酸甘油脂的差異,可採用變異數相等T分配之信賴區間 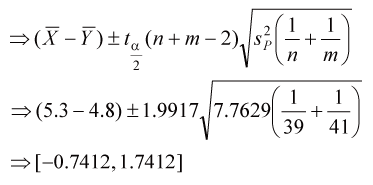
|
|||||||||
| 合理上來說應該採用法一原始資料來作信賴區間才是會出題者的本意,但本卷未附 之查表值,所以考場中同學大多數都會採用法二的作法,反倒失去出題者原意,甚為可惜。 |
擬答
|
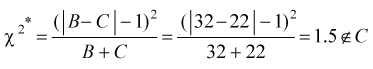
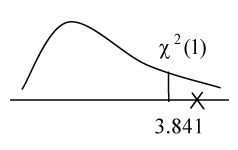
| 擬答 利用Fisher Z轉換 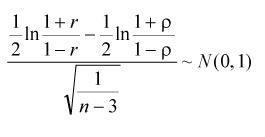 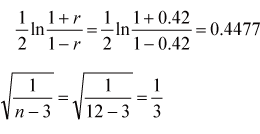
(註:題意不甚清楚,原考試卷上敘述「參與健檢民眾」應為100位,但出題者應是想問那6 位家族成員的2 個家庭共12人的樣本才對。) 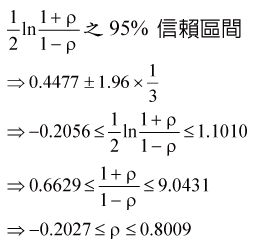
或直接帶公式,得相關係數的95%信賴區間 下限: 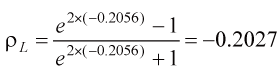 ; ;上限: 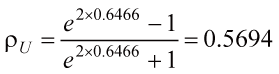
|