110專技高考公衛師
生物統計學
申論題
$X$:不合格藥品數
$X~Bin(n=24,p=0.04)$
合格的機率為
$P(X≤1)$
=$P(X=0)$+$P(X=1)$
=$C^{24}_0 0.04^0 .0.96^{24} + C^{24}_1 0.04^1 .0.96^{23} $
=0.7508
在此考慮近似卜瓦松分配求解
$X~Bin(n=24,p=0.04)$ → $Poi(\lambda = 24 \times 0.04 = 0.96)$
$f(x)=\dfrac{0.96^x・e^{-0.96}}{x!}$ , $x=0,1,2,...∞ $
合格的機率為
$P(X≤1)$
=$P(X=0)$+$P(X=1)$
$=\dfrac{0.96^0・e^{-0.96}}{0!}$ + $\dfrac{0.96^1・e^{-0.96}}{1!}$
= $1.96 \times 0.3829 $
= $0.7505$
- 考慮迴歸模式
ln(p/q)= -2.0591 + $0.5211X_1$
經常飲用含糖飲料
$X_1 = 1$ :
$ln(p_1/q_1)$ =-2.0591 + 0.5211 × 1
無經常飲用含糖飲料
$X_1 = 0$ :
$ln(p_0/q_0)$ =-2.0591 + 0.5211 × 0
所以 $ln \left( \dfrac{p_1 / q_1}{p_0 / q_0} \right) $= ln(OR)=0.5211
粗勝算比 OR = $e^{0.5211}$ = 1.6839
- 從干擾因子條件來說,年齡是外在因子,且年齡是罹患第二型糖尿病的危險因子,且與年齡與經常飲用市售含糖飲料有關(合理猜想為負相關),所以年齡為干擾因子;就多變量統計分析結果來說,邏輯式迴歸模式是否控制了年齡,迴歸係數估計值有所不同:
ln(p/q)= -2.0591 + $0.5211X_1$
ln(p/q)= -2.0591 + $1.3364X_1$ + $0.1418X_2$
可知透過模式控制後的勝算比產生了離零偏差,為負干擾。綜合上述,年齡是經常飲用市售含糖飲料與第二型糖尿病的干擾因子。 - 考慮多變量邏輯斯迴歸模式
ln(p/q)= -9.2834 + $1.1883X_1$ + $0.1521X_2$ + $1.1246X_3$ + $2.1371X_4$
經常飲用含糖飲料:$X_1$=1,
$ln(p_1/q_1)$= -9.2834 + $1.1883\times 1$ + $0.1521X_2$ + $1.1246X_3$ + $2.1371X_4$
無經常飲用含糖飲料:$X_1=0$,
$ln(p_1/q_1)$= -9.2834 + $1.1883\times 0$ + $0.1521X_2$ + $1.1246X_3$ + $2.1371X_4$
所以 $ln \left( \dfrac{p_1 / q_1}{p_0 / q_0} \right) = ln(OR)=1.1883 $
調整後勝算比 $OR=e^{1.1883}=3.2815$
其95%信賴區間為 $e ^ {1.1883 \pm 1.96\times 0.5784}$
$\Rightarrow \left \lbrack e^{0.054636},e^{2.32164} \right \rbrack $
$\Rightarrow \left \lbrack 1.0562,10.1957 \right \rbrack$
將資料整理如下
| 月份 | 一月 | 二月 | 三月 | 四月 | 五月 | 六月 |
|---|---|---|---|---|---|---|
| 觀察值$O_i$ | 1 | 3 | 2 | 7 | 14 | 20 |
| 期望值$E_i$ | 12 | 12 | 12 | 12 | 12 | 12 |
| 七月 | 八月 | 九月 | 十月 | 十一月 | 十二月 | 總計 |
| 37 | 33 | 16 | 6 | 2 | 3 | 144 |
| 12 | 12 | 12 | 12 | 12 | 12 | 144 |
$H_1$ :溺水死亡事件有月份聚集現象
α= 0.05
檢定統計量 $X^{2^*}$
=$\sum \dfrac {(O_i - E_i)^2}{E_i}$
=$\dfrac {(1-12)^2}{12}+...+ \dfrac {(3-12)^2}{12} $
= 141.17
自由度 $df = 12 - 1 = 11$
因為 $P(X^2 > 19.68,df = 11) = 0.05$
所以 $p-value = P(X^2(11)> 141.17)< 0.05$
臨界值為 $X^2_{0.05}(11)$ = 19.68
拒絕$H_0$ ,有顯著證據說溺水死亡事件有月份聚集現象
選擇題
| (B) | 1 | 若有一種新型篩檢工具可以在1 天內即測出是否有D 病,該工具敏感度(sensitivity)為85%,特異度(specificity)為95%。張先生使用此工具篩檢得知結果為陽性,則張先生實際確診為D 病的機率為何?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 2 | 新冠肺炎從2020 年開始肆虐至今,已經至少出現7 種變異病毒,愈多人沒打疫苗,病毒變異的機會愈大。某一機構之員工30%為外勤人員,70%為內勤人員。已知60%的外勤人員和40%的內勤人員皆已打疫苗,若隨機抽取一沒打疫苗者,請問其為內勤人員之機率為何?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 3 | 下列有關描述性統計的敘述,何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 4 | 卡方分布(chi-square distribution)的平均值與下列那一個數值相等?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (B) | 5 | 為了解市面上販賣的飲料中某物質X 的平均值,隨機抽取40 杯飲料的樣本,這40 杯飲料X的平均值為10。假設X 在母群體及此樣本的標準差剛好皆為4。下列敘述何者錯誤?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 6 | 一群過重的成年人被隨機分派成兩組,一組進入減重計畫,一組作為對照組,半年之後用t 檢定評估兩組受試者體重改變的差異,參加減重計畫的受試者體重平均減少5 公斤,對照組平均減少1 公斤,二組體重改變平均值差異的95%信賴區間是1 公斤到7 公斤。下列敘述何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 7 | 下列關於樣本數與統計檢定力(statistical power)的敘述,何者錯誤?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 8 | 為了估計臺灣30 歲至60 歲男性的平均血壓的收縮壓,研究者挑選一家健身俱樂部50 位30歲至60 歲的男性會員測量其血壓。根據中央極限定理,下列敘述何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 9 | 關於平均數之信賴區間的敘述,下列何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (B) | 10 | 根據調查,肺癌患者治療後復發的機率為15%。現有一醫生想了解這樣的機率是否正確,該醫生希望95%的信賴水準下,估計誤差不超過1%,最少應該收集多少樣本才足夠?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 11 | 在一臨床醫學研究中,有N 位病況相當之病人被隨機安排在K 種治療方式,若欲了解是否至少有一治療方式,治療後其病人之平均病情分數與其他治療方式有統計上顯著差異,研究者得到下列變異數分析表:
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 12 | 當抽樣的樣本數增加時,樣本平均值的標準誤(standard error)會發生何種變化?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 13 | 某調查想了解民眾對某政策是否贊同,100 位受訪者中,有55 位回答「贊同」,45 位回答「不贊同」,同意比例的點估計為55%。有關估算同意比例的95%信賴區間(95% Confidence interval; 95%CI)的方法,下列敘述何者錯誤?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 14 | 某抽樣調查甲地區高中生嘗試吸菸狀況,調查結果樣本中30%曾吸菸,估計嘗試吸菸率的95%信賴區間(下界,上界)得(27%, 33%)。已知全國高中吸菸率為25%,試檢定甲地區高中生嘗試吸菸率是否與全國高中生有顯著差異(顯著水準設0.05)。下列敘述何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 15 | 承上題,若顯著水準(significance level)設定為0.05,下列敘述何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (B) | 16 | 某機構針對甲乙兩個部門進行服務滿意度調查,收集甲乙各100 位民眾(總共200 位民眾)分別對服務人員勾選的滿意度程度,非常不滿意勾1、不滿意勾2、普通勾3、滿意勾4、非常滿意勾5。若要檢定甲乙兩部門滿意程度中位數是否有統計上顯著差異,下列何種方法最適當?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 17 | 進行全國性大規模健康行為與狀況調查時,完成隨機抽樣後,若要檢定樣本與全國母體在年齡及性別上的分布是否一致時,下列統計方法何者最適當?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 18 | 下列為10 對雙胞胎成年後身體質量指數(BMI)數據:
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 19 | 下表為A、B 兩個地區發生疾病D 的分布:
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 20 | 某社區健康服務中心辦理健康促進活動,100 位民眾報名參加,其中一項活動為調查參加者對愛滋病的傳染途徑是否了解。每個人在活動開始及結束各回答同一個問題一次,1 表示答對,0 表示答錯,以下為民眾的資料示意表(僅列出前10 位)。若要檢定參加前後民眾對愛滋病傳染途徑了解是否有顯著差異,下列那一個統計方法最適當?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 21 | 以下是一個統計車禍發生時,機車騎士是否有戴安全帽和是否發生頭部外傷之間關係的二乘二列聯表:
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (B) | 22 | 下列關於單因子變異數分析(one-way analysis of variance)的敘述,何者錯誤?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 23 | 下列關於兩獨立樣本t 檢定(two-sample independent t test)的敘述,何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (B) | 24 | 臨床心理師將18 位病情相當的輕度失智症患者完全隨機分派到下表三種治療方式,每一種治療方式有6 人,持續進行3 個月的治療,之後接受憂鬱量表的測量。治療後的憂鬱量表測量分數描述統計量如下,分數越高表示憂鬱傾向越高。臨床心理師執行變異數分析,請問此變異數分析表中之組間變異平方和(Sum of Squares Between Groups)大約為何?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 25 | 下列何者不是無母數方法?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (B) | 26 | 下列關於解釋變數之間的共線性(collinearity)何者錯誤?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 27 | 189 位足部雞眼(foot corns)的患者,94 位接受手術治療,另外95 位接受非手術性治療。下列是進行邏輯式迴歸分析治療成功與否(成功設為1, 失敗設為0)的結果:
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 28 | 下列關於迴歸分析變數選擇的敘述,何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 29 | 隨機抽樣兒童醫院654 位18 歲以下兒童和青少年,測量他們的身高(單位:公分)及每分鐘最大通氣量(單位:公升)。以最大通氣量為依變項,身高作為解釋變項,進行簡單線性迴歸分析。結果發現,身高的迴歸係數為0.05 公升/公分,標準誤為0.001,判定係數為0.75。下圖為模型的殘差圖(residual plot),橫座標是身高,縱座標是殘差。
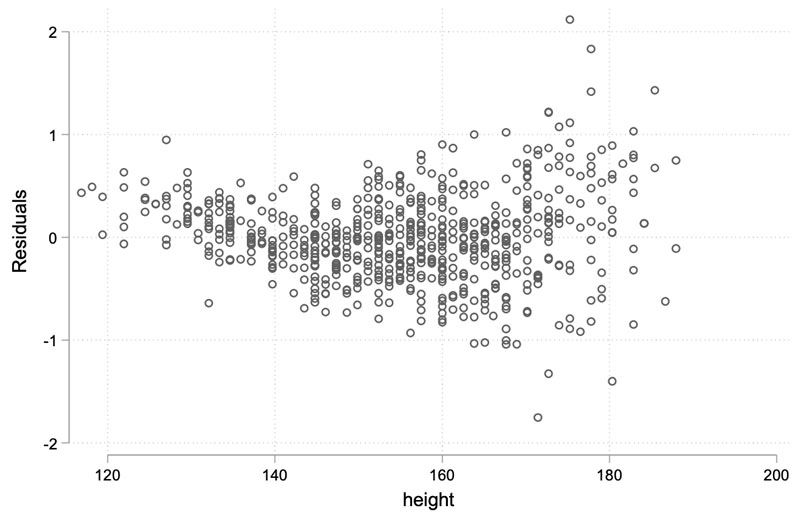 下列敘述何者錯誤? 下列敘述何者錯誤?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 30 | 針對189 名出生嬰兒的體重(單位:公克),和嬰兒母親的變項,包括母親年齡(單位:年)、母親懷孕前體重(單位:公斤)和母親是否有高血壓(有高血壓設為1,沒有設為0)進行複迴歸分析,得到以下結果: 出生體重=2240.29+6.33×母親年齡+11.77×母親懷孕前體重-591.12×高血壓下列敘述何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 31 | 在北北基隨機抽樣N 位中學九年級生,資料顯示每日運動時間及閱讀能力皆為常態分布,而且運動時間較多的學生,其閱讀能力較高;若使用普通最小平方法:以每日運動時間(分鐘)來預測閱讀能力(分數),得到下表,請問線性迴歸係數(又稱斜率)大約為何?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 32 | 下圖為根據三組不同資料的(X,Y)散布圖及應用普通最小平方法之線性迴歸線,依此三組資料所得的決定係數(Coefficient of Determination)大小順序為何?
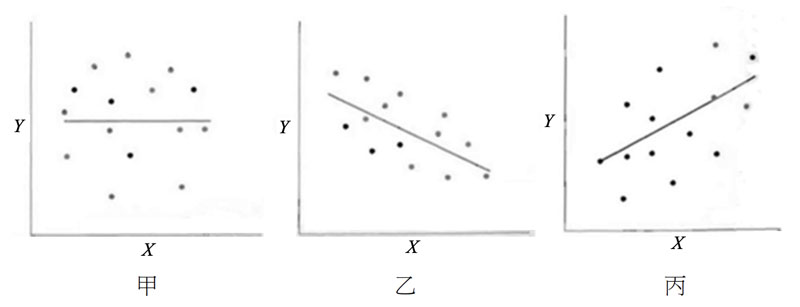
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 33 | 在線性迴歸模式中,所謂普通最小平方法意即最小化何值?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 34 | 某調查比較兩個地區某心血管風險指標分數(連續變項)的平均值是否不同,但兩個地區的年齡及性別組成不同,需要估算校正年齡及性別後之兩組平均值的差,下列那一個方法最適當?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (C) | 35 | 某研究想探討社區長者身體活動情況(Group)與某心血管類疾病(D 病)的關係。令D 為二分類變項,D=1 表示有D 病,D=0 表示無D 病;Group=1 表示有規律運動習慣,Group=0表示無運動習慣。以下為依變項為D 的迴歸模式分析結果,B 代表迴歸係數,OR 代表勝算比(Odds Ratio),95%CI OR 代表勝算比的95%信賴區間。
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 36 | 61 位晚期大腸直腸癌病人,34 位接受合併化學治療,27 位接受單一化學治療,利用Cox 風險比例模型,針對死亡風險分析得到以下結果:
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (B) | 37 | 某研究調查大學生身體活動(PA)與BMI 的關係。以下為線性迴歸模式的係數估計,BMI 為依變項(dependent variable),PA 為自變項(independent variable)。其中PA 為身體活動的類別,1 代表經常身體活動("活動組"),0 代表很少身體活動("少動組")。
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (A) | 38 | 42 位急性白血病的病人隨機分派接受標靶治療或化學治療,觀察事件是病人死亡,下圖是Kaplan-Meier 存活分析圖: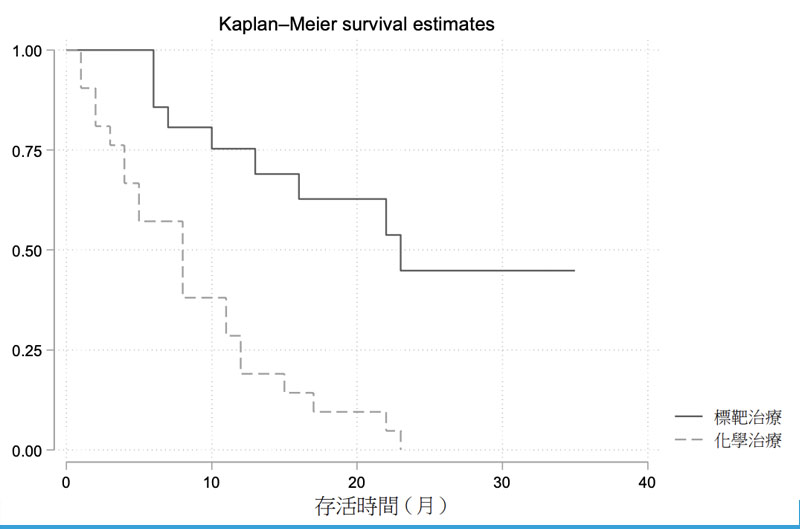 在本研究中,沒有病人中途退出,所有病人不是在觀察過程中死亡,就是在研究結束時仍存活。根據上圖,下列敘述何者正確?
在本研究中,沒有病人中途退出,所有病人不是在觀察過程中死亡,就是在研究結束時仍存活。根據上圖,下列敘述何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (B) | 39 | 下圖為總共50 位病人的存活曲線,虛線為男性,實線為女性,跨在每條線上的小細直線標示為設限(censor)。有關存活曲線,下列敘述何者正確?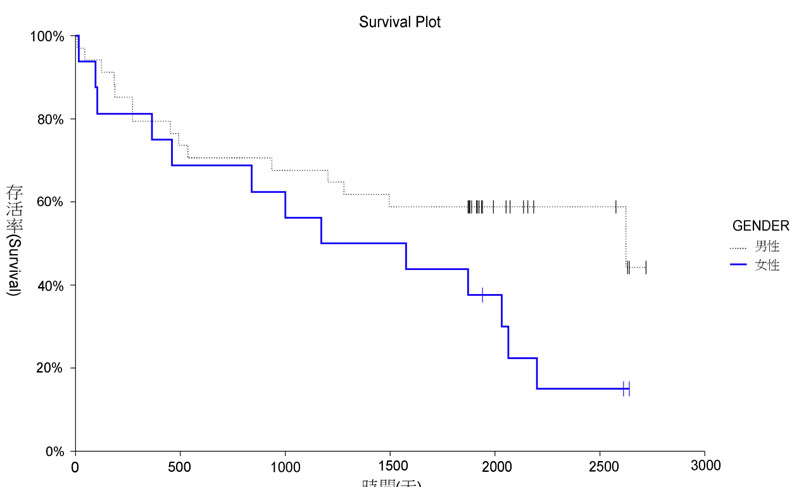
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| (D) | 40 | 病人的Kaplan-Meier 存活分析圖形裡,存活函數是一個遞減的階梯函數(step function)。如果觀察的事件是病人的死亡,關於階梯函數每往下一個階梯代表的意義,下列敘述何者正確?
| ||||||||||||||||||||||||||||||||||||||||||||||||||
※本站所有內容皆為志光教育科技集團版權所有,未經同意請勿任意複製、轉載、發行或刊他處。