- 沒有吃早餐的學童$X$上課精神不振比例 $ \hat{p_1} = \cfrac {64}{300}$
- 有吃早餐的學童$X$上課精神不振比例$ \hat{p_2} = \cfrac {51}{400}$
- 沒有吃早餐與有吃早餐的學童,上課精神不振比例差值的95%信賴區間為
$ (\hat{p_1} - \hat{p_2} ) $ $ \pm Z_{0.025} \sqrt { \cfrac{ \hat{p_1} ( 1- \hat{p_1} )}{ n_1} + \cfrac{ \hat{p_2} ( 1- \hat{p_2} )}{ n_2} } $
$ \Rightarrow ( \cfrac{64}{300} - \cfrac {51}{400} )$ $ \pm 1.96 \sqrt { \cfrac { \cfrac{64}{300} \times \cfrac{236}{300}}{300} + \cfrac { \cfrac{51}{400} \times \cfrac{349}{400}}{400} }$
$ \Rightarrow [ 0.0291,0.1426 ]$
112專技高考公衛師
生物統計學
申論題
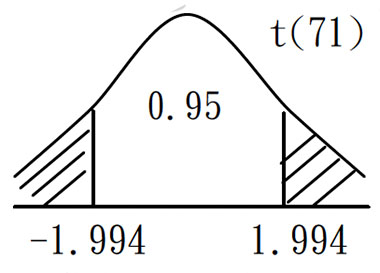
$ H_0:\mu =128 $
$ H_1:\mu \ne 128$
$ α=0.05$
$ T^*$ $ =\cfrac { \bar{X} - \mu_0 }{ S/ \sqrt{n}}$ $ = \cfrac{126.1-128}{15.2 / \sqrt{72}}$ $ -1.06 \notin C $
$C: \{ | T^* | > t_{0.975,71} = 1.994 \}$
不拒絕 $H_0$ ,沒有證據說該公司35歲到44歲的男性高階主管的平均血液收縮壓與該國男性平均收縮壓不同
-
在兩獨立母體變異數相同的情況下
$ s_p^2 = \cfrac {(n-1) s_x^2 + (m-1) s_y^2 }{ n+m-2}$
$ = \cfrac {(10-1).11.52^2 + (10-1).7.66^2 }{10+10-2}$$ = 96.693$
$t = \cfrac{ \bar{X} - \bar{Y} }{ \sqrt{ s_p^2 (\cfrac{1}{n} + \cfrac{1}{m}) }}$ $ = \cfrac{ 74-60 }{ \sqrt{ 95.693 (\cfrac{1}{10} + \cfrac{1}{10}) }}$
$ = 3.200$ - 採用變異分析
$ SST = \sum \sum (\bar{X}_{i.} - \bar{X}_{..})^2 $ $ =\sum n_i (\bar{X}_{i.} - \bar{X}_{..})^2 $
$ 10 \times (60-67)^2 $ + $ 10 \times(74-67)^2 $ $=980$
$ SSE = \sum \sum (\bar{X}_{ij} - \bar{X}_{i.})^2 $ $ = \sum (n-1)S_i^2 $
$ = (10-1) \times 11.52^2 $ + $ (10-1) \times 7.66^2 $ $=1722.474 $
ANOVA 表
所以 $F = 10.241$SS df MS F 組間 980 1 980 10.241 組內 1722.474 18 95.693 總和 2702.474 19 - $F = 10.241$ = $ t^2 = 3.200^2 $
所以檢定兩組平均數是否相同,採用獨立樣本t檢定與ANOVA等價
選擇題
| (B) | 1 | 某社區衛生局統計每日上午9:00至12:00,平均就診人數為10 人,請問 9月1日當天就診人數少於3人的機率為何?$(e^{-10} = 4.54×10^{-5})$
|
|||||||||||||||||||||||
| (C) | 2 | 以下盒形圖(boxplot)來自世代研究調查資料,將資料中有中風者及無中風者的年齡以盒形圖繪製出其分布,利用此圖的訊息,對於中風與否之年齡分布描述,選出較合適的選項?
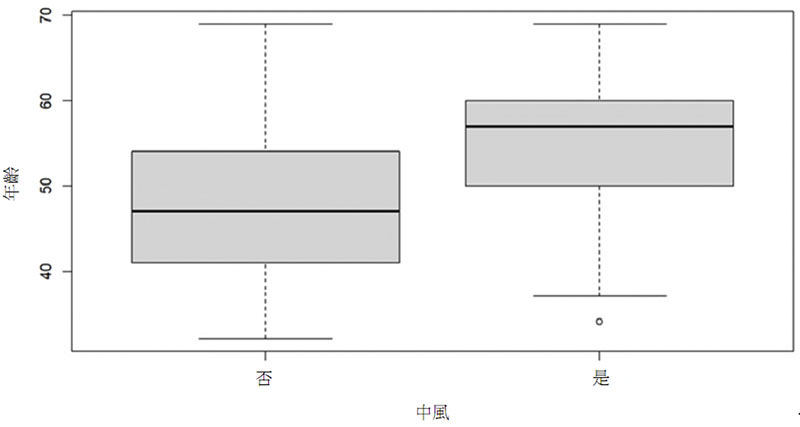
| |||||||||||||||||||||||
| (D) | 3 | 在某大學新生體檢中,發現大學生健康狀況明顯較往年差,該校患有糖尿病的學生中男生之比例為0.7,該校沒有糖尿病學生中男生的比例為0.5,且年輕族群(18-20歲)糖尿病盛行率為1%,請問該校男學生中,患有糖尿病的比例為何?(四捨五入至小數第三位,選出最接近的答案)
| |||||||||||||||||||||||
| (A) | 4 | 某大學大一統計成績服從常態分配,平均數為78分,標準差為5,共有500位修習統計學,請問有一位同學分數為88分,請問其排名為何?PR 值為何?(選出最接近選項)
| |||||||||||||||||||||||
| (B) | 5 | 在流行病學研究中,常利用性別及年齡配對,來了解暴露及疾病之相關性。以下資料為世代研究(cohort study)收集而來,想了解抽菸對於肺癌之影響,以不同條件暴露狀況進行性別及年齡配對,以一位有抽菸者和一位未抽菸者進行性別及年齡的配對,再觀察兩人是否有罹患肺癌,並檢定抽菸和肺癌之相關性。請針對此資料的檢定結果,選出正確的選項。(檢定時皆不進行連續型修正)
| |||||||||||||||||||||||
| (D) | 6 | 想了解戴口罩對於預防新冠肺炎是否有效益,共收集 100 人,進行回顧式研究,其中有得病及未得病者,分別各有 50人,請他們回顧過去一個月戴口罩之狀況,資料如下,下列描述何者錯誤?
|
|||||||||||||||||||||||
| (B) | 7 | 研究顯示慢跑及快走皆是有益身心之運動,國外研究顯示在既定的公里數下,慢跑所需熱量較快走多,在此收集以下資料,想驗證此結果;在進行相同的公里數下(1.6公里)所需消耗之熱量如下(單位:大卡):
| |||||||||||||||||||||||
| (A) | 8 | 研究者欲瞭解具有某項飲食習慣的有無,是否會導致某疾病的發生,他將研究資料整理如下: 具有該項飲食習慣、但沒有罹病:400 人 具有該項飲食習慣、也有罹病:100 人 不具該項飲食習慣、也沒有罹病:200 人 不具該項飲食習慣、但有罹病:300 人 若研究者將上述資料置入 logistic regression 中,則可計算出,具有該項飲食習慣者罹病之Crude Odds Ratio 為何?
| |||||||||||||||||||||||
| (B) | 9 | 若針對宜蘭地區居民進行腰圍之測量,抽出 500 位居民(無遺失值) ,其樣本腰圍平均數為78.89公分、樣本腰圍標準差為9.72 公分。男性為250人,其樣本腰圍平均數為83.07公分、標準差為9.99公分;女性為250人,其樣本腰圍平均數為74.70公分、標準差為9.67公分。下列何者正確?
| |||||||||||||||||||||||
| (A) | 10 | 最近研究發現"人工甜味劑「阿斯巴甜」可能對人類致癌",一般食品的規範中,食品每100公克含糖量不超過0.5公克,即可宣稱「無糖」 ,這些宣稱無糖的食品,卻添加了許多人工甜味劑,長期而言,非全然對健康無害。若要想檢測此食品是否可宣稱「無糖」,我們抽出數個樣本進行檢測,測量每100公克的含糖量,以下對於虛無假設及對立假設的設定,何者正確?
|
|||||||||||||||||||||||
| (C) | 11 | 我們可以利用中央極限定理的結果,建構$\mu $的95%信賴區間,稱為(a, b) ,針對此信賴區間的描述,何者正確?
| |||||||||||||||||||||||
| (C) | 12 | 在心血管疾病的研究中,腰圍為重要的影響因子,控制腰圍大小為預防心血管疾病管道之一,我們想了解腰圍大小(Y)和收縮壓(X)之相關性。利用簡單線性迴歸模型$ \mu_{Y|X} = α + \beta X $或皮爾森(Pearson)相關係數($\rho $)了解兩者間之相關性,下面描述何者錯誤?(假設腰圍、收縮壓為常態分配)
| |||||||||||||||||||||||
| (B) | 13 | 在治療自體免疫性疾病的藥物中,除了非類固醇抗發炎藥(NSAID)外,還有免疫抑制劑的選擇。以下資料來自 200 位疾病嚴重度相似的自體免疫性疾病患者,有 100 位接受 Drug 治療(Drug=0,為參考組),有100位接受免疫抑制劑的治療(Drug=1),觀察治療半年後疾病狀況是否有改善(Y=1:有改善;Y=0:無改善),在調整年齡(Age)、性別(Gender=0,女性(參考組);Gender=1,男性)後,下列式子及下表為多變項模型及其估計結果(顯著水準為0.05)。下列描述何者正確? logit={Pr(Y=1 | $Drug$,$Gender$,$Age $)} $ = α+ \beta_1 \times Drug$ + $\beta_2 \times Gender$ + $\beta_3 \times Age$
|
|||||||||||||||||||||||
| (A) | 14 | 在心血管疾病的研究中,腰圍為重要的影響因子,控制腰圍大小為預防心血管疾病管道之一,我們想了解腰圍大小($Y$)和收縮壓($X_1$)之相關性,並考慮調整年齡($X_2$)及性別($X_3$) ,男性為1,女性為0,女性為參考組)。以下利用簡單線性迴歸及複迴歸模型,探討腰圍和收縮壓之相關性,請計算模型三中$\beta_1$之95%信賴區間估計。(此資料樣本數為5019,遺失值變數最多為3%,顯著水準為0.05)
模型一$ \mu_{Y|X_1} $ $= α + \beta_1 X_1 $ 模型二$ \mu_{Y|X_1,X_2,X_3} $ $= α + \beta_1 X_1 + \beta_2 X_2 $ 模型三$ \mu_{Y|X_1,X_2,X_3} $ $= α + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_3 $ 模型四$ \mu_{Y|X_1,X_2,X_3} $ $= α + \beta_1 X_1 + \beta_2 X_2 + \beta_2 X_3 $ $+ \beta_4 (X_1 \times X_3)$ 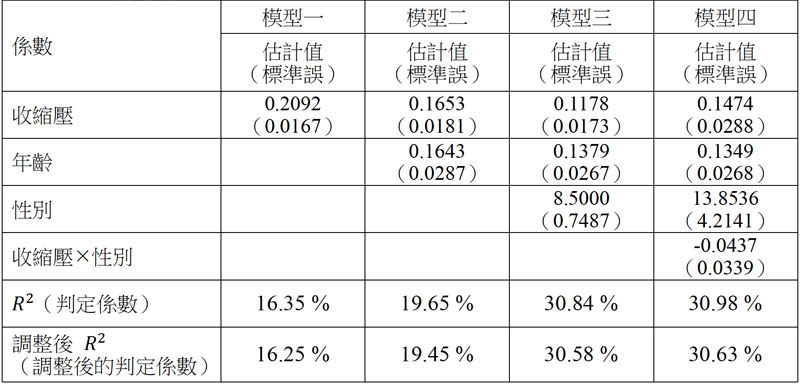
| |||||||||||||||||||||||
| (B) | 15 | 承上題,對於模型一、二、三、四之描述,何者錯誤?
| |||||||||||||||||||||||
| (A) | 16 | 肺癌發生率為每十萬人口36 人,為臺灣前10 大癌症之一,以下為某醫學中心,肺癌存活率之資料(以月為單位),是利用Kaplan-Meier 估計方法得到,gender=0 為女性,gender=1 為男性,在曲線上"+"為設限(censor),以下描述何者錯誤?
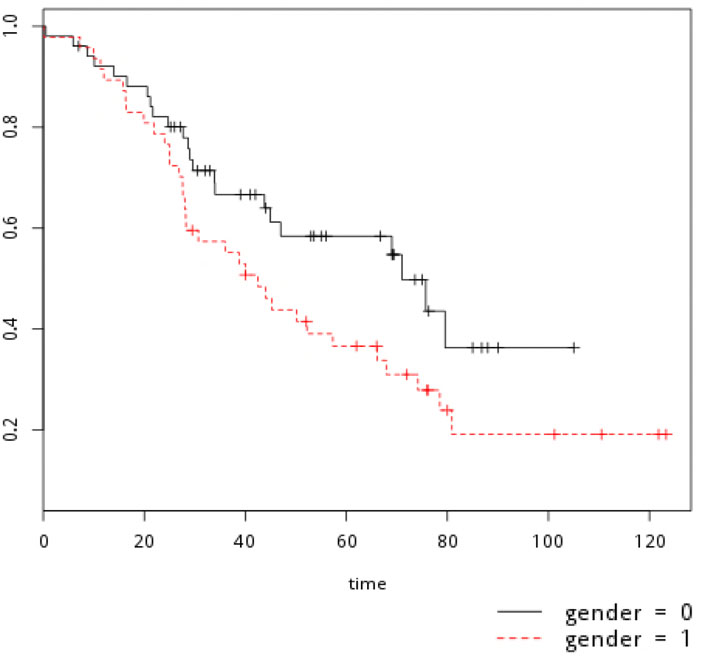
| |||||||||||||||||||||||
| (D) | 17 | 承上題,我們想了解男性、女性之存活曲線是否有差異,利用以下方法進行檢定,請問以下描述,何者正確?(顯著水準為0.05)
| |||||||||||||||||||||||
| (A) | 18 | 我們利用 Cox PH model(Cox proportional hazard model)進行影響因肺癌死亡之風險因子的探討,以因肺癌死亡為事件發生,並記錄從追踪到因肺癌死亡發生之時間,模型之解釋變項為性別(男性、女性,女性為參考組)、年齡、抽菸程度(從未抽菸、過去曾抽菸現在無抽菸、現在有抽菸,現在有抽菸為參考組),依據以下分析結果,那些為影響存活之因子,請選出正確選項:
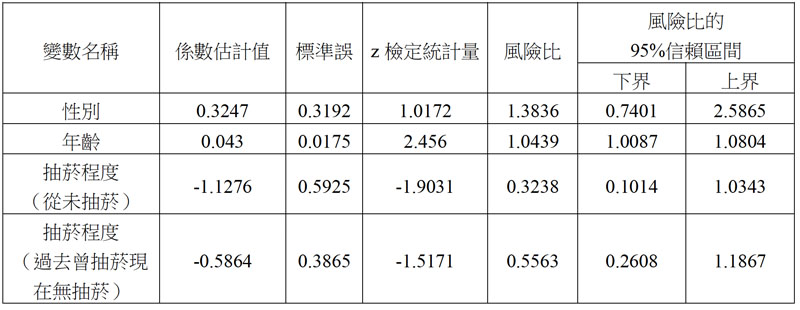
| |||||||||||||||||||||||
| (B) | 19 | 承上題,依據上題分析結果,對於模型參數之解釋何者正確?
| |||||||||||||||||||||||
| (B) | 20 | 在一個Mean=Median=Mode的常態分布中,加入若干個極大值後,請問下列敘述何者正確?(假設仍然只有一個Mode)
| |||||||||||||||||||||||
| (A) | 21 | 在盒型圖(boxplot)中,圖形中央四邊形所對應的數值範圍,涵蓋了這個變數多少比例的觀察值?(α為顯著水準)
| |||||||||||||||||||||||
| (C) | 22 | 在執行完「變異數分析」的檢定之後,碰到下面那種情況時,需要再進行「事後檢定」(或稱「多重比較」)?
| |||||||||||||||||||||||
| (D) | 23 | 在《莊子.齊物論》有一則寓言:養猴人跟猴子們說,以後早上餵三升橡實,下午餵四升橡實,但猴子們聽了很不高興,因為早上吃太少,於是,養猴人說,那改成早上餵四升,下午餵三升,猴子們就很高興(此即朝三暮四的典故)。假設養猴人對這些猴子進行這兩種餵食方式的滿意度調查,結果如下(a,b,c,d為猴子的個數):
| |||||||||||||||||||||||
| (A) | 24 | 將某兩個變數置入simple linear regression後,得到其決定係數為0.64,若將這兩個變數進行相關分析,則其相關係數應為下列何者?
| |||||||||||||||||||||||
| (B) | 25 | 某研究者收集了 10 名罕見疾病患者的發病年齡,若欲比較男性和女性之發病年齡是否有差異,則該使用何種統計方法來進行檢定?
| |||||||||||||||||||||||
| (C) | 26 | 在下列四種統計檢定方法中,共有幾種方法可以對自變數進行調整 (adjustment,或稱控制)? ①Simple linear regression ②Logistic regression ③General linear model ④Cox proportional hazard model
| |||||||||||||||||||||||
| (B) | 27 | Kruskal-Wallis test 的虛無假設為下列何者?
| |||||||||||||||||||||||
| (D) | 28 | 在使用統計軟體進行性別、血型、身高(以上三項為自變數)對於體重(依變數)的複迴歸分析時,如果在報表中有出現一項下表中的結果:
| |||||||||||||||||||||||
| (B) | 29 | 在某次選舉中,研究者對三位候選人進行支持度的民意調查,結果發現,甲、乙、丙三位候選人的支持度分別為30%、27%、20%。試問:該研究者還需要下列那一種指標,才能判斷候選人之間的支持度是不分軒輊,或是具有統計上的顯著差異?
| |||||||||||||||||||||||
| (D) | 30 | 在實務研究上,若發現欲對一個2×3列聯表進行檢定時,其中有兩個細格(cell)的期望值不符合Pearson's chi-square test的使用前提。試問:在進行下列那一項動作之後,就能夠有機會且合理地使用該檢定方法?
| |||||||||||||||||||||||
| (B) | 31 | 有一檢測之陽性預測值為60%,令其敏感度為100%,可得之陰性預測值為何?
| |||||||||||||||||||||||
| (C) | 32 | 承上題,令其特異度為33%及群體得病率為50%,請問檢測陽性者為得病之條件機率為何? P (D+|T+) = P (D+)*sensitivity/ (P (D+)*sensitivity+ (1-P (D))*(1-specificity))
| |||||||||||||||||||||||
| (D) | 33 | 下列四種資料尺度中,那一種的等級(或稱數值化程度)是最低的?
| |||||||||||||||||||||||
| 有一多中心體外反搏介入研究(MUST-EECP),其中 71 人為個案組,66 人為對照組,其心絞痛年平均值(標準差)分別為8.56(7.88)對4.5(4.06)。請回答第34題至第36題: | |||||||||||||||||||||||||
| (A) | 34 | 請問其標準誤分別為何? 標準誤=標準差 / $ \sqrt{樣本大小}$
| |||||||||||||||||||||||
| (B) | 35 | 請問個案組vs 對照組心絞痛年95%信賴區間下限vs上限分別為何? 95%信賴區間=平均值±1.96×標準誤
| |||||||||||||||||||||||
| (A) | 36 | 請問個案組與對照組二組心絞痛年平均值之差異應用何種統計方法檢定?
| |||||||||||||||||||||||
| (C) | 37 | 如表,設定的顯著性水平(通常為0.05),請問下列敘述何者最不適當?
| |||||||||||||||||||||||
| (D) | 38 | 承上題,請問下列敘述何者最不適當?
| |||||||||||||||||||||||
| (C) | 39 | 想針對臺灣四個地區(北、中、南、東)進行 BMI 之調查,是否不同區域之 BMI 之平均數會有差異,以下為 ANOVA 的分析結果,資料無遺失值。在顯著水準為 0.05 時,針對下表ANOVA的結果,選出正確選項?
說明:$Pr(F>F_{(p,3,4823)})$$=p,F_{(p,3,4823)}$為$(1-p)$th百分數
$ F_{0.05,2,4824} = 2.9976 $,
$ F_{0.05,3,4823} = 2.6068 $,
$ F_{0.05,4,4822} = 2.3738 $,
$ F_{0.05,5,4821} = 2.2160 $,
$ F_{0.05,4824,2} = 19.4955$,
$ F_{0.05,4823,3} = 8.5270$,
$ F_{0.05,4822,4} = 5.628824$,
$ F_{0.05,4821,5} = 4.3658$
| |||||||||||||||||||||||
| (C) | 40 | 承上題,所採取的檢定方式,其虛無假設及對立假設為何?
|
|||||||||||||||||||||||
※本站所有內容皆為志光教育科技集團版權所有,未經同意請勿任意複製、轉載、發行或刊他處。