《題型解析》:本題結合了單母體平均數之信賴區間與雙母體平均差的假設檢定,因為試卷並無合適的t表,所以建議皆可採用大樣本Z分配的做法即可,111年高考二級衛技出了類似考題。
《命中特區》:生物統計學/王瑋|志光出版,頁175~176;生物統計學精選500題全解/王瑋|志光出版,頁199~200。
- 假設 X 代表吸菸組FEV1,Y代表非吸菸組FEV1
吸菸組FEV1平均值的95%信賴區間為
$\bar{X} \pm Z_{0.025} \cfrac{ \sigma _x }{\sqrt{n}}$
$\Rightarrow 3.3 \pm 1.96・\cfrac{ 0.68 }{\sqrt{224}}$
$\Rightarrow [ 3.2109,3.3891]$ -
$H_0:\mu_x= \mu_y$ $H_1:\mu_x \ne \mu_y$
$a = 0.05$
$ Z^* $ $= \cfrac { \bar{X} - \bar{Y} }{ \sqrt{\cfrac{\sigma_x^2}{n_X} + \cfrac{\sigma_Y^2}{n_Y }}}$ $= \cfrac { 3.3 - 2.92 }{ \sqrt{\cfrac{0.68^2}{224} + \cfrac{0.71^2}{116}}}$
$= 4.75\in C $
$ C:\{ |Z^*|> Z_{0.025} =1.96\}$
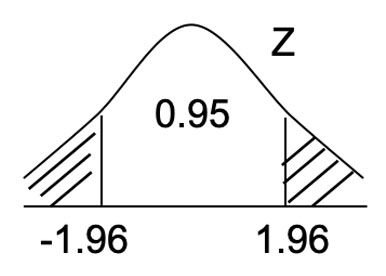
拒絕 $H_0$,有顯著的證據說・
兩組第一秒用力呼氣量平均值有差異